【GCP】Cloud Vision APIで顔検出をやってみた
はじめに
Cloud Vision APIを使用して「ローカル画像での顔の検出」を動かしてみました。
今回試したのは以下となります。
- Cloud Vision APIの有効化と初期設定
- Cloud Vision APIの実行した結果をjsonに保存
- jsonファイルを元に、画像から顔の部分を切り出す
Cloud Vision APIの有効化と初期設定
Cloud Vision APIの有効化
APIとサービス→ライブラリ
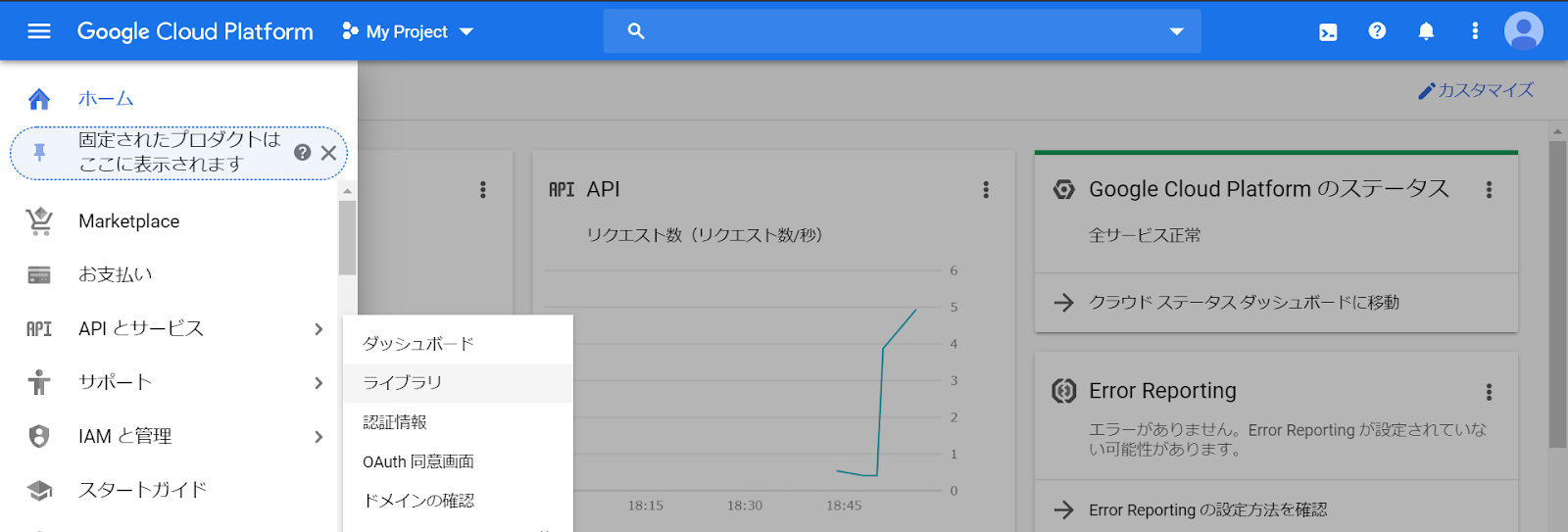
「Cloud Vision API」を選択
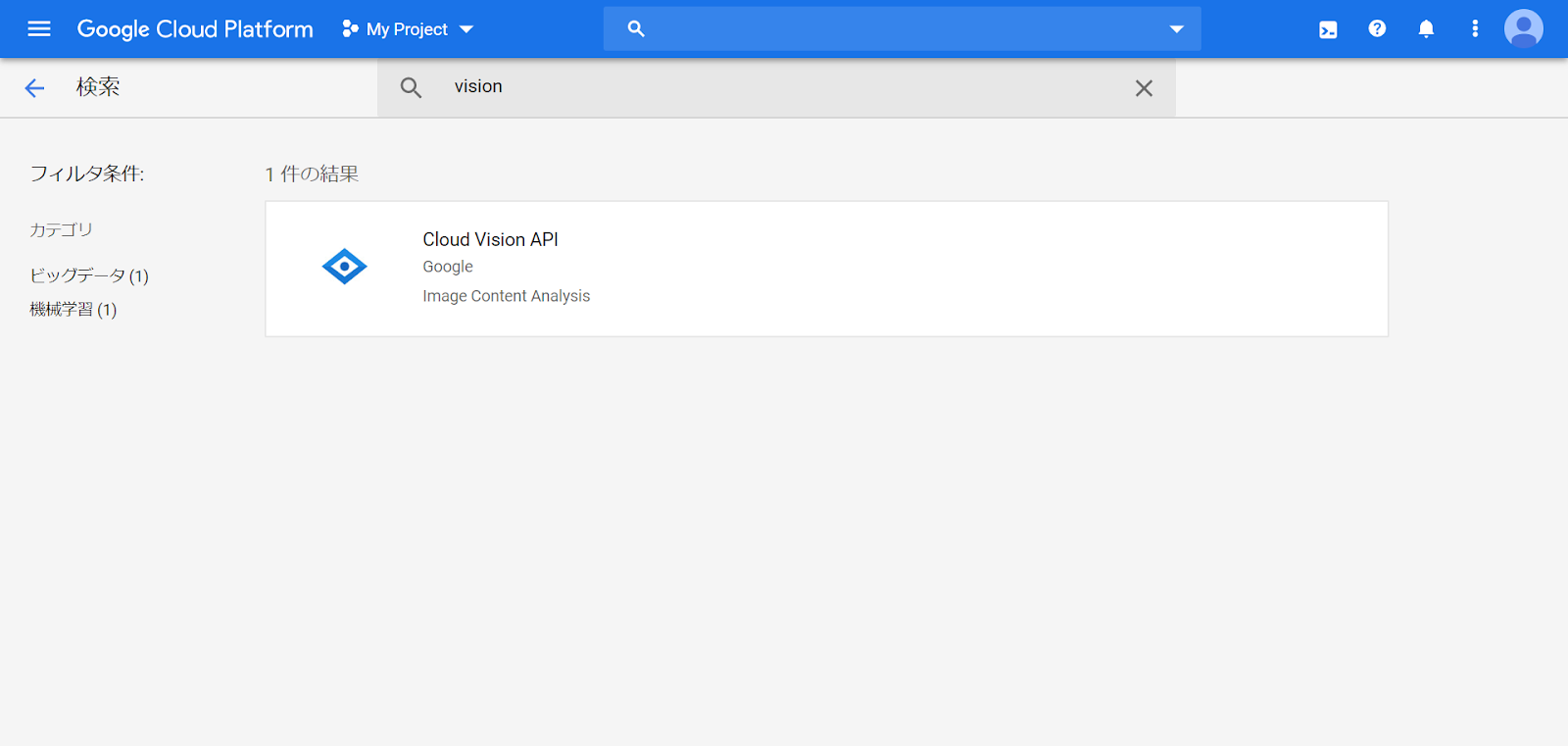
「有効にする」ボタンを選択
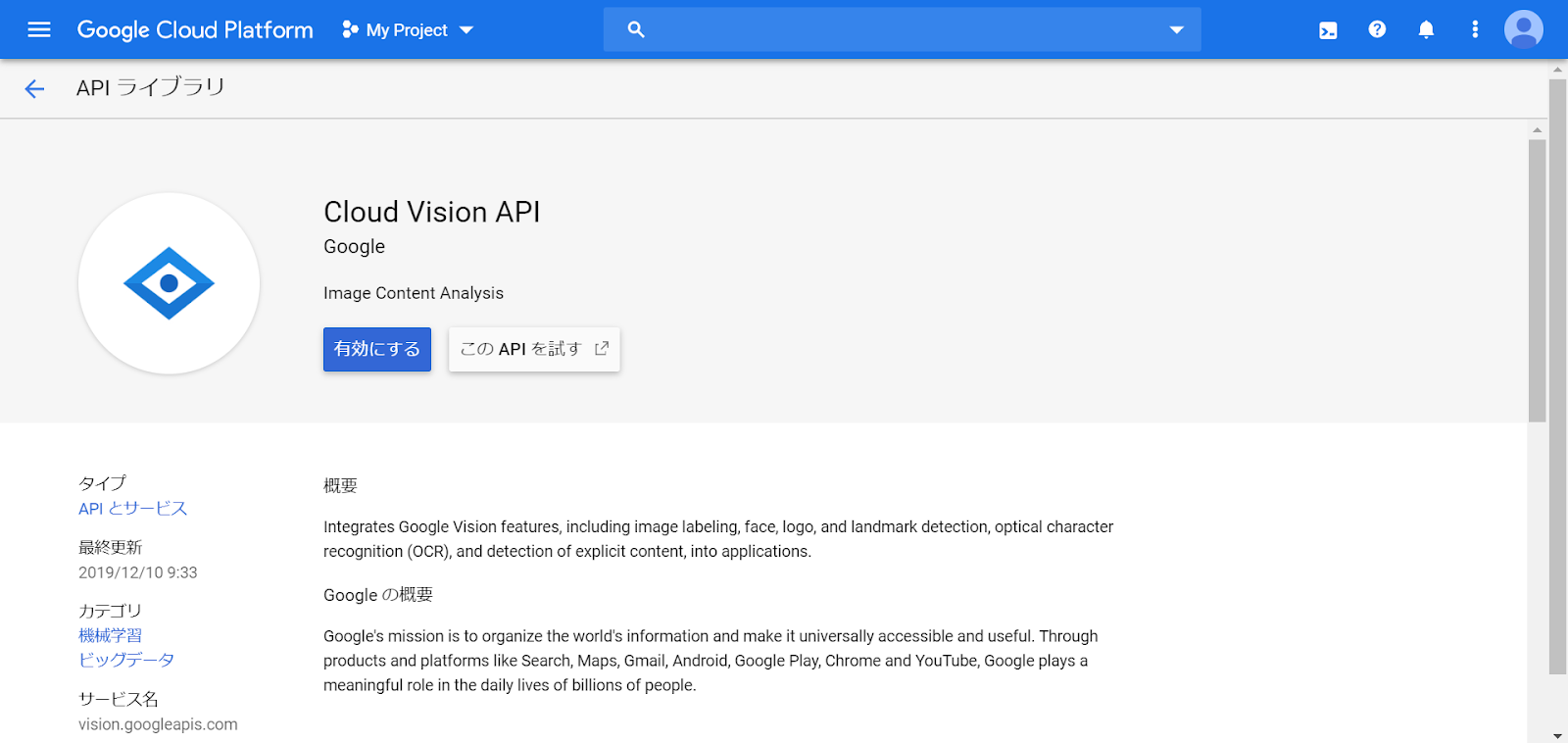
「認証情報を作成」を選択
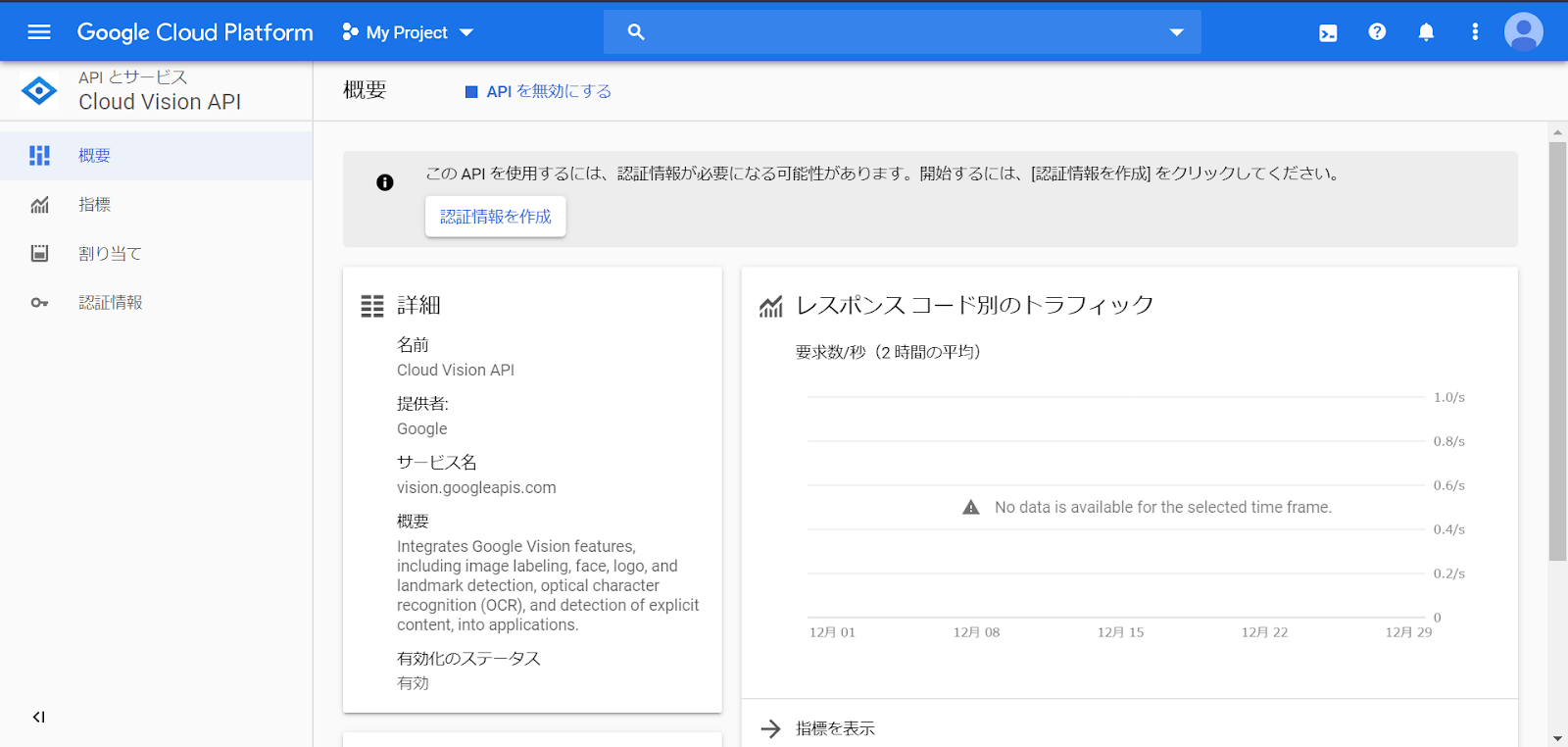
「プロジェクトへの認証情報の追加」に入力をします。
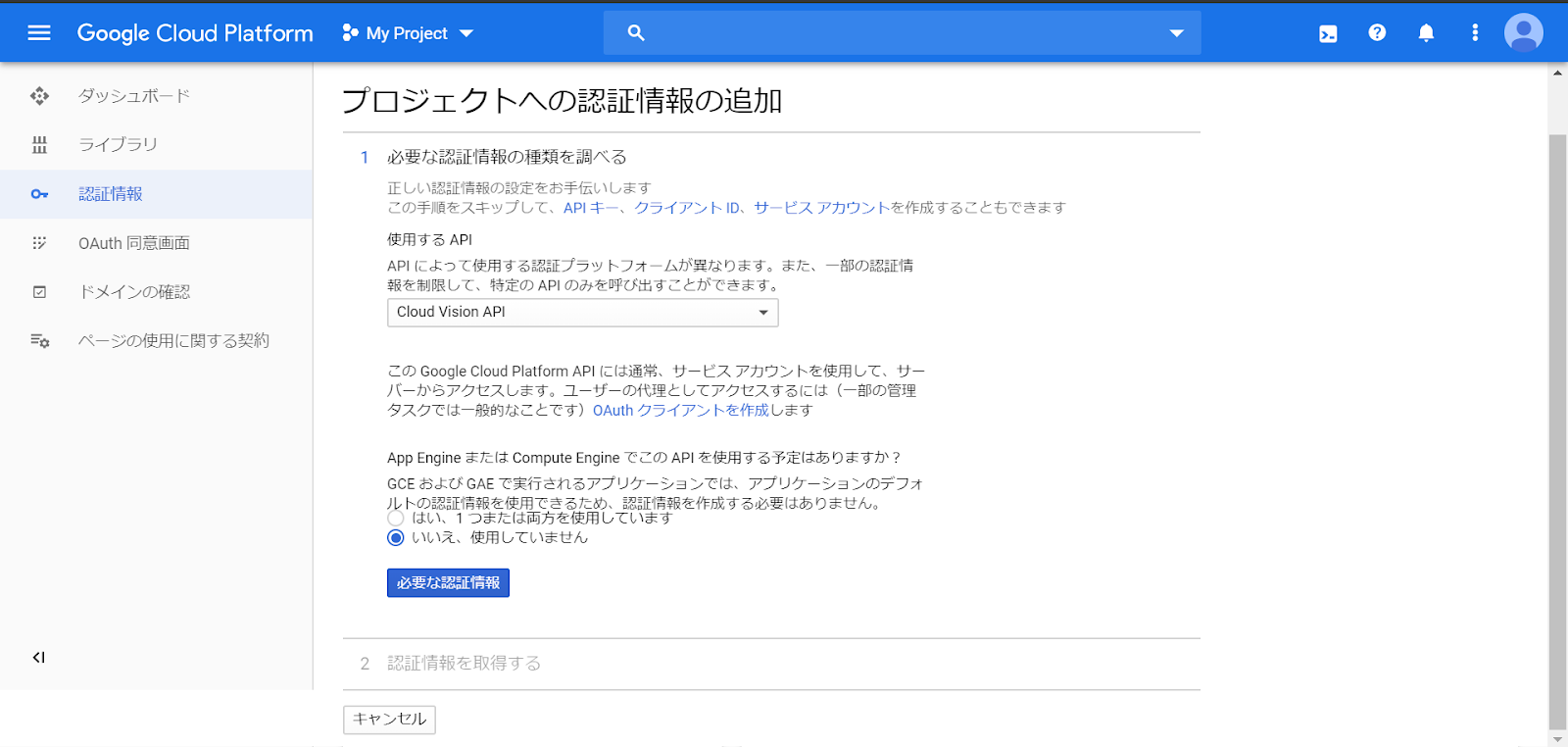
今回は「オーナー」権限にしました。
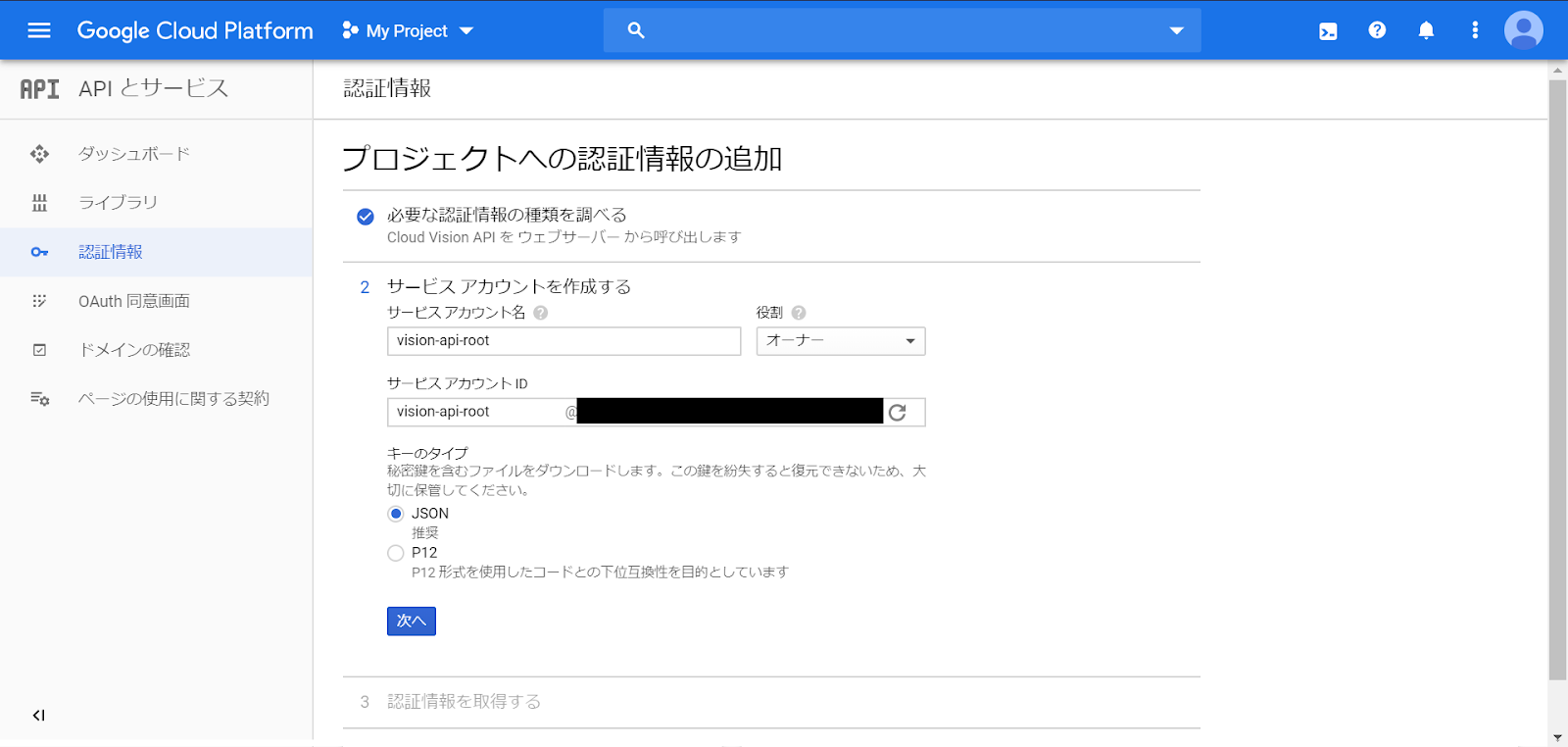
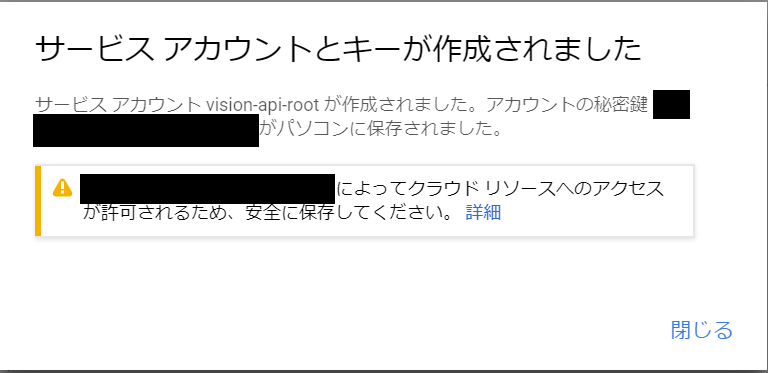
認証情報用のjsonファイルがダウンロードできます。
Cloud Vision APIの初期設定
環境変数の設定
環境変数に GOOGLE_APPLICATION_CREDENTIALS を追加し、先ほどダウンロードしたjsonファイルのパスを指定します。
“C:\Users\usename\[FILE_NAME].json"
クライアント ライブラリをインストール
pip install --upgrade google-cloud-vision処理を実行
この処理でコードで以下の事を実現しています。
- Cloud Vision APIの実行
- Cloud Vision APIの実行結果をjsonに保存
- Cloud Vision APIの実行結果を元に画像から顔の部分を切り出す
from google.cloud import vision
from google.cloud.vision import types
from pathlib import Path
from google.protobuf.json_format import MessageToJson
import io
import os
import shutil
from PIL import Image
import json
import time
def detect_face(input_file):
from google.cloud import vision
client = vision.ImageAnnotatorClient()
content = input_file.read()
image = types.Image(content=content)
return client.face_detection(image=image)
def crop_face(image, faces, output_filename):
im = Image.open(image)
for face in faces:
position = [(vertex.get("x") if vertex.get("x") is not None else 0, vertex.get("y") if vertex.get("y") is not None else 0)
for vertex in face.get("boundingPoly").get("vertices")]
im_crop_outside = im.crop((position[0][0], position[0][1], position[2][0], position[2][1]))
if im_crop_outside.mode != "RGB":
im_crop_outside = im_crop_outside.convert("RGB")
im_crop_outside.save(output_filename, quality=95)
def main():
input_path = ".\input"
output_path = ".\output"
p = Path(input_path)
input_files = list(sorted(p.glob('*.jpg'), key=os.path.getmtime))
for input_file in input_files:
with open(input_file, 'rb') as image:
text = detect_face(image)
image.seek(0)
json_file = Path(output_path, input_file.stem+".json")
if not json_file.exists():
with open(json_file, 'w') as f:
response = detect_face(image)
json_file.write_text(MessageToJson(response))
json_files = list(sorted(Path(output_path).glob('*.json'), key=os.path.getmtime))
for json_file in enumerate(json_files):
with open(json_file, 'rb') as data_file:
json_data = json.loads(data_file.read().decode('utf-8')).get("faceAnnotations")
if not json_data:
continue
image = Path(input_path, json_file.stem+".jpg")
output_image = Path(output_path, json_file.stem+".jpg")
crop_face(image, json_data, output_image)
if __name__ == "__main__":
main()Cloud Vision APIの実行
Cloud Vision APIのFace Detectionを呼んでいます。
ここは公式のソースコードの流用です。
def detect_face(input_file):
from google.cloud import vision
client = vision.ImageAnnotatorClient()
content = input_file.read()
image = types.Image(content=content)
return client.face_detection(image=image)Cloud Vision APIの実行結果をjsonに保存
input_pathのjpgファイルを順番に処理して、detect_faceを呼んでいます。
detect_faceの戻り値はprotobuf形式なのでMessageToJsonでjsonに変換したものを保存しています。
def main():
input_path = ".\input"
output_path = ".\output"
p = Path(input_path)
input_files = list(sorted(p.glob('*.jpg'), key=os.path.getmtime))
for input_file in input_files:
with open(input_file, 'rb') as image:
json_file = Path(output_path, input_file.stem+".json")
if not json_file.exists():
with open(json_file, 'w') as f:
response = detect_face(image)
json_file.write_text(MessageToJson(response))Cloud Vision APIの実行結果を元に画像から顔の部分を切り出す
元の画像から顔の部分だけを切り出す処理になります。
「if vertex.get(“x") is not None else 0」の部分は、座標が0の時はjsonに含まれないので0を設定しています。※備考参照
def crop_face(image, faces, output_filename):
im = Image.open(image)
for face in faces:
position = [(vertex.get("x") if vertex.get("x") is not None else 0, vertex.get("y") if vertex.get("y") is not None else 0)
for vertex in face.get("boundingPoly").get("vertices")]
im_crop_outside = im.crop((position[0][0], position[0][1], position[2][0], position[2][1]))
if im_crop_outside.mode != "RGB":
im_crop_outside = im_crop_outside.convert("RGB")
im_crop_outside.save(output_filename, quality=95)保存したjsonファイルの数だけcrop_faceを呼んでいます。
「if not json_data:」の部分はCloud Vision APIが画像ファイルに顔認識できなかった場合、jsonにfaceAnnotationsが含まれません。
その場合は後続処理を実行しないようにしています。
json_files = list(sorted(Path(output_path).glob('*.json'), key=os.path.getmtime))
for json_file in enumerate(json_files):
with open(json_file, 'rb') as data_file:
json_data = json.loads(data_file.read().decode('utf-8')).get("faceAnnotations")
if not json_data:
continue
image = Path(input_path, json_file.stem+".jpg")
output_image = Path(output_path, json_file.stem+".jpg")
crop_face(image, json_data, output_image)備考
座標のサンプル
座標が0の時はjsonに含まれないようです。
"boundingPoly": {
"vertices": [
{
"x": 1
},
{
"x": 100
},
{
"x": 100,
"y": 150
},
{
"x": 1,
"y": 150
}
]
}顔が認識できない場合
空のjsonになります。
{}